

 13 March, 2020
13 March, 2020 





The Socioeconomic High-resolution Rural-Urban Geographic Dataset on India (SHRUG) is a new data source that describes socioeconomic development in India. In this post, Asher, Lunt, and Novosad describe its construction and particular advantages over existing datasets for research on economic development.
Access to economic data is a major constraint on research and policy-making in developing countries. There is a perverse equilibrium where academics based abroad often have better access to country data than researchers based in developing countries. Quality is as pernicious a barrier as access: available data are usually poorly cleaned, idiosyncratic, and inadequately documented, such that they require months of expensive labour to prepare for any kind of meaningful use.
Data in the 21st century: Water everywhere and not a drop to drink
The majority of research and policy in India (and most developing countries) is based on data from nationally representative household and firm surveys. Due to budget constraints, these surveys are sparse, geographically imprecise, and weakly integrated with each other. National sample surveys are useful for calculating national statistics and understanding the broad distribution of socioeconomic outcomes. However, they provide little information on local geographic variation, even though the majority of variation in socioeconomic status occurs on a small geographic scale. In India, over half of the variation in village-level consumption is below the district level, and yet districts are the lowest strata in nearly all of India’s major surveys. Project-focused surveys (like those used in randomised control trials) generate precise geographic information, but these are run on such a small scale that they may not be very useful outside of the projects for which they are designed.
At the same time, government programme administration is increasingly electronic, generating vast streams of geographically precise and detailed data. But these are not widely used for research in developing countries. Two key barriers to adoption of administrative data are: (i) these data are rarely made accessible to the public in an easily-analysed format; and (ii) these data are often narrow in scope and difficult to link to other datasets.
Even when researchers do gain access and put in the hundreds of hours required to clean these datasets, the resulting data outputs are often not made available to others in an accessible format. Perversely, the resources required to work with administrative data like these are often concentrated at top universities, so that residents of developing countries may have less access to data on their own countries than researchers in the US and Europe.
The SHRUG as data: High-resolution broad-spectrum economic data covering 1990-2018
Our research team and collaborators have put in thousands of hours to carefully link India’s core administrative records on towns and villages together over the last 25 years. The culmination of this work is the Socioeconomic High Resolution Rural-Urban Geographic data platform for India (the SHRUG).
The SHRUG is both a dataset and a data platform. As a dataset, it describes every town (n=5000), village (n=500,000), and legislative constituency (n=4000) in India over the last 25 years. It contains variables characterising their demographics, living standards, industrial composition, public goods, environmental amenities, election results, and politician assets and criminality, among other fields. These data are open and freely accessible.
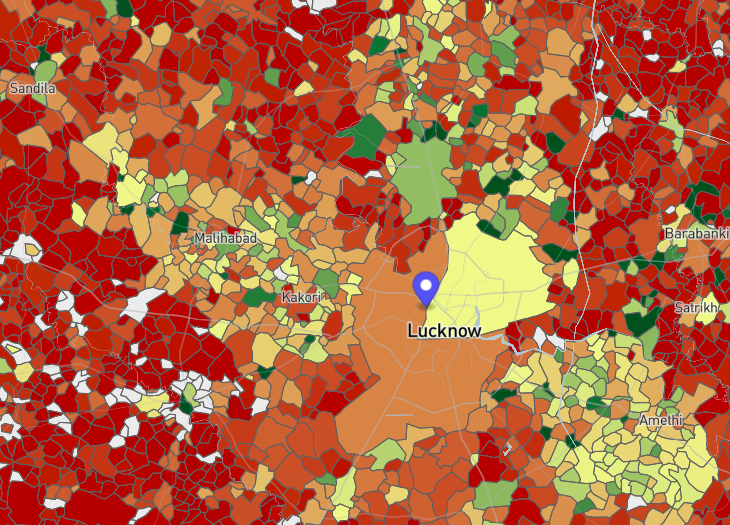
Non-farm employment per capita in the vicinity of Lucknow.
Source: SHRUG Atlas
Particular advantages of the SHRUG are its high geographic resolution and wide range of data. Here are four examples of how the SHRUG may be particularly useful:
- Substantial variation in socioeconomic outcomes and in programmes occurs at a very local level. The SHRUG makes it possible to study these programmes at the level of that variation rather than at more aggregate levels where programme variation is highly attenuated. For example, we used SHRUG to study the impact of India’s gigantic rural roads programme (Asher and Novosad 2020); to do this, it was necessary to measure and distinguish between socioeconomic characteristics of villages only a few kilometers apart. In principle, one can study these programmes at aggregate levels (which districts built more roads than others), but there is a huge advantage to having universal high-resolution data, both for statistical power and to take advantage of natural experiments that exist at the local level.
- Unlike district-level data sources, SHRUG identifies outcomes at the city/town level. Urbanisation and economic activity in cities is one of the central components of development in India; city-level data is crucial for understanding how cities are growing.
- SHRUG is the first multidimensional economic dataset that identifies outcomes at the level of legislative constituencies, making possible the analysis of politics and development at the level at which representatives are elected.
- Researchers running field experiments often use a population census village as the sampling unit for new experimental studies, but they know very little about villages at the sampling stage. Now, they can immediately link their village list to SHRUG and can a 25-year economic history of each village in the sample, testing for divergent trends even before survey collection has entered the field.
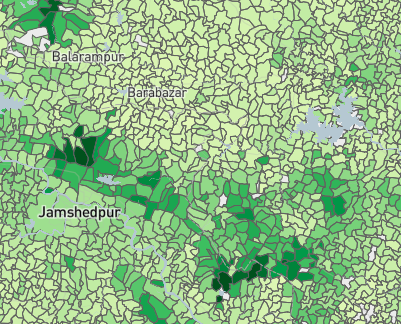
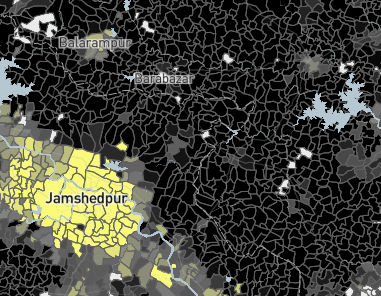
Forest cover and night lights in the vicinity of Lucknow.
Source: SHRUG Atlas
The SHRUG as collaborative platform: Raising the externalities from research
An underappreciated problem in research today is that researchers do not always face incentives to share the data that they have created. A researcher with unique data may prefer to keep it private for two reasons. First, they may not want to get scooped on future research projects. Second, it takes a lot of additional work to make data comprehensible to the public, and the researcher may not be willing to put in that additional work once they already have a publication.
But this is a terrible equilibrium for the progress of knowledge. Hundreds of researchers are replicating the same laborious data cleaning work without sharing their outputs. Many research programmes do not achieve their potential because of a lack of access to data sources that others have used successfully. Policymakers in developing countries often have less access to useful data than research teams. Data, like other knowledge, is non-rival; in an ideal world, the fixed cost of generating new data is paid once and the whole world benefits from this investment.
We have designed the SHRUG to address both the technical and the incentive problems associated with data sharing. On the technical side, we are making it as straightforward as possible to link new datasets to the SHRUG, making it easy for researchers to share their data in a readily usable format. For large-scale administrative datasets, our team at Development Data Lab will even assist researchers and policymakers in linking their data to SHRUG to make it widely available.
On the incentive side, we have designed the SHRUG to maximise career benefits from contribution. Data in the SHRUG remains attributable to its contributors. SHRUG users cite every component of SHRUG that they use, ensuring that researchers get credit for their contributions. The SHRUG has already been downloaded thousands of times; as it becomes more popular, it will be an increasingly valuable way to enable other researchers to discover one’s research and data. Further, SHRUG is released under a copyleft license; this requires that new non-proprietary data sources that are linked to SHRUG be made open when their related academic papers are published.
Toward a more open equilibrium
There is already a wealth of data on the implementation of government programs that is beyond the ability of any single research team to exploit. Our goal with the SHRUG is to create a backbone for high resolution data that facilitates sharing of information and opens this data wealth to researchers both in and outside of India.
We are continually adding to the SHRUG. At this time, the SHRUG describes: (i) demographics and public goods in every town and village in India from 1991 to 2011; (ii) employment and location of every firm in India (1990-2013); (iii) legislative election results (1980-2018); (iv) remotely sensed night lights (1994-2013); (v) remotely sensed forest cover (2000-2014); (vi) the labour share in agriculture and consumption estimates from the 2012 Socioeconomic and Caste Census; and (vii) administrative data from the implementation of India’s national rural roads programme (2000-2015). While many scholars are already using it in their research, its usefulness will grow tremendously as we and other researchers add more data to the platform.
Anyone interested in the SHRUG can browse the paper or codebook, can download data via the SHRUG web site, and can explore the geographic distribution of some of the key SHRUG variables via our beta SHRUG Atlas.
Further Reading
- Asher, S, T Lunt, R Matsuura and P Novosad (2019), ‘The Socioeconomic High-resolution Rural-Urban Geographic Dataset on India (SHRUG)’, International Growth Centre Working Paper.
- Asher, Sam and Paul Novosad (2020), “Rural Roads and Local Economic Development”, American Economic Review, 110 (3): 797-823.

Comments will be held for moderation. Your contact information will not be made public.