

 21 August, 2015
21 August, 2015 




Recent experiences, especially from Scandinavian countries, show that opening administrative data sources can substantially improve public policymaking. In this article, Pande and Blum contend that while investment in data infrastructure is needed to produce and use statistics, the decision to collect and open data also depends on political economy considerations. Such forces are particularly strong in India and pose a major constraint on effective policy reform.
We recently asked tax administrators in Pakistan – a country with notoriously low tax compliance – about work challenges. We assumed that underreporting would be the crux of their woes, as is usually the case.
Data is not a natural resource that simply needs to be harvested. The plan for tracking the United Nation’s (UN) Millennium Development Goals (MDGs), defined in 2000, acknowledged weaknesses of certain data sources such as sporadic surveys and one-off studies, and named options that would be more reliable, thus suggesting a roadmap toward a comprehensive and sustainable data infrastructure. Yet, short-term reporting needs instead led to a reliance on those old methods.
Critics have pointed out that the data on MDG progress is patchy and impossible to corroborate. World Bank researchers report that only 77 of the 155 countries they studied collect reliable data on poverty. The UN itself issued a 2014 report stating that data deprivation “can lead to the denial of basic rights, and for the planet, to continued environmental degradation,” and calling for a “data revolution.”
The UN is currently creating a list of Sustainable Development Goals (SDGs), intended to take the place of the MDG, which will shape how governments and Non-Governmental Organisations (NGOs) allocate an estimated US$2.5 trillion of aid over the next 15 years. The UN forwarded a proposal to the General Assembly on 17 July and will finalise the SDGs in September. Goal 17 vaguely addresses data deprivation, by stating an aim to build on existing initiatives and “support statistical capacity building in developing countries.”
Yes, poor countries require investment in the infrastructure needed to collect, collate, and open up their administrative data to the public, particularly researchers. But whether countries produce and use statistics depends on more than infrastructure – the decision to collect, collate and open data also depends on political economy considerations, which thus far have been left out of the conversation.
The political economy of data collection
The
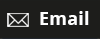
Figure 1. Percentage of years with poverty data by income group
 Note: The horizontal axis maps countries by income quintile.
Note: The horizontal axis maps countries by income quintile.
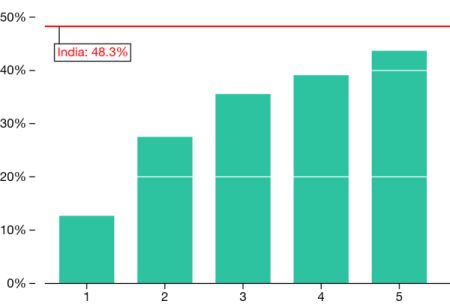
But India’s data exceptionalism doesn’t extend to measuring whether its citizens are successfully investing in acquiring the tools to escape poverty — for instance, by getting an education. Arguably, this missing information has limited India’s ability to pull the right policy levers to accelerate poverty reduction.
Figure 2. Percentage of years with education data by income group
If we look at the historical context, it appears that political economy considerations influenced India’s decision to collect data. In 1950, on the eve of India’s first election as an independent nation, the Prime Minister, Jawaharlal Nehru, established India’s National Sample Survey Organisation (NSS) and charged it with conducting comprehensive surveys on household consumption, expenditure and livelihoods. Given the popular sentiment that colonialism had impoverished Indians, as well as Nehru’s belief in socialist planning institutions, the choice to invest in the infrastructure necessary to produce
Fast forward to 2000, when the OECD started offering all countries the Programme for International Student Assessment (PISA). This represented an opportunity for India to invest in data on learning by its schoolchildren, as opposed to just enrolment. However, the country could no longer blame erstwhile colonial powers if its efforts to get children behind desks had failed to produce actual knowledge. India decided to test the waters in 2009 by having two high-performing states take part. When the surveys were complete and India’s showcase states, Himachal Pradesh and Tamil Nadu, were ranked 72 and 73 of regions tested – beating out only Kyrgyzstan – India exited PISA.
A keystone of the political economy of reform literature is Dani Rodrik and Raquel Fernandez’s finding that reforms that benefit the majority may fail if it is easier to identify the reform losers than the potential winners. Given Indian teachers’ and educational administrators’ knowledge of the dire reality, and the uncertainty surrounding the benefits of achievement tests for the majority of India’s schoolchildren, it is easy to understand why India opted out.
Yet, reforms do occur – often aided by data, not in spite of it. More recently, Rodrik argued in the Journal of Economic Perspectives that ideas pioneered by powerful policy entrepreneurs can sometimes
When Brazil began participating in PISA in 2000, like India, it figured quite low in the performance ranking. Yet, some politicians saw this as an opportunity. According to The Economist, “Rich parents used private schools; poor ones knew too little to understand how badly their children were being taught
Reducing Brazil’s rising economic inequality, which in turn was associated with the country’s poor schooling record, had been a key focus of
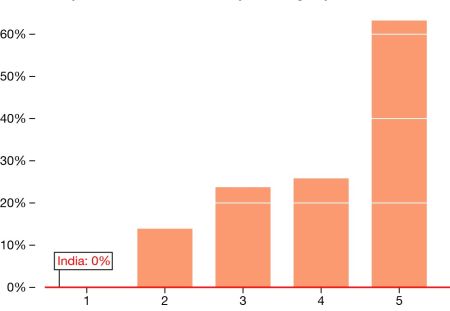
Indeed, Brazil’s initial PISA results helped Cardoso justify his schooling reforms, and to further push a comprehensive system of measuring education results and school quality. Strikingly, this period saw a significant increase in the availability of educational indicators per source, as Brazil used its existing framework of data collection to obtain richer information on a crucial subject. And these investments paid off: Brazil’s PISA ranking has improved dramatically, from second to last in science and last in math in 2003 to the 78th and 80th percentile, respectively, in 2012. In math, Brazil is the country with the largest performance gain since 2003.
Figure 3. Indicators per data source, Brazil
Data and researchers: If you build it, will they come?
In a recent training session conducted under the aegis of our research group, Evidence for Policy Design’s (EPoD) collaboration with the UK’s Department for International Development (DFID)’s Building Capacity to Use Research Evidence programme, we asked Indian administrators what held them back from making data that has already been collected public. Their response was that if researchers wanted to see the data, they could file a request under the Freedom of Information Act.
Over the last half-century, Freedom of Information Acts
But a set of figures provided via a Freedom of Information request offers a keyhole through which a researcher can view a small slice of the data a government collects. That does not compare to giving researchers hands-on access to entire administrative datasets.
Driven by advances in computer technology that allowed analysis to be conducted confidentially and remotely over the Internet, and by an increasing demand from researchers and policymakers, Scandinavian countries started improving researchers’ access to the administrative data they collect in the
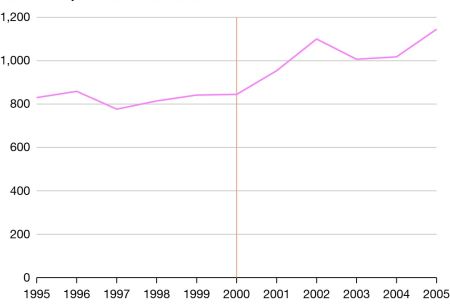
Consider the case of Denmark, which facilitated access to de-identified data from one central hub in 2005, and further extended data access in 2008. A simple time-series plot shows that few papers were being written about Denmark before the change to data accessibility, but when researchers were granted entry, that number shot up.
Figure 4. Publications based on Danish administrative data
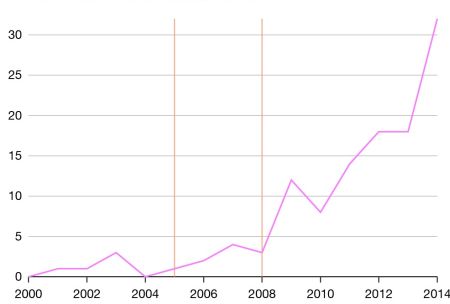
This has mattered for how
But even as the arc of history bends toward open data, we have seen countries move in the opposite direction – again, acting on political motivations. In March of this year, the Tanzanian parliament, facing an October election, introduced a law requiring any published data to be endorsed by the National Bureau of Statistics, essentially giving the government the ability to bury reports by the press and research by scholars. While it is hard to imagine this law gaining traction, the very fact that it passed suggests that some in power wish to keep a tight hold on data as elections approach. Furthermore, even among those wealthy countries whose administrative datasets could feed hugely beneficial research, many (example, Japan) have largely restricted access.
Set the cycle in motion
Across the world, States that want to redistribute fairly and finance public goods effectively – that want to be friendly to outside analysis and unfriendly to cheats – require data.
Returning to Pakistan’s tax administrators, the data that would make their jobs easier, not to mention more productive, was there at some point. Sums were paid into an account, they just weren’t treated as data. We believe that if you recognise data and its value, collect it and make it accessible, the ecosystem will take over. The availability of data will spur analysis, creating further feedback loops: more information on a problem, and a political debate about
The tricky part is creating coalitions of policymakers, researchers and citizen groups that will succeed in instituting such data systems. The political economy of data production responds to external as well as internal pressures. Come September, the UN should not just announce the SDGs but create clear mechanisms to recognise and reward countries that institute robust infrastructure for
An abridged version of this article first appeared in the Washington Post’s Monkey Cage blog. Data visualisations were done by Eric Dodge, EPoD.

Comments will be held for moderation. Your contact information will not be made public.